Detecting silent errors in the wild: Combining two novel approaches to quickly detect silent data corruptions at scale
Written by Lucky Wilson | KGTO Writer on April 5, 2022
Silent data corruptions (SDCs), data errors that go undetected by the larger system, are a widespread problem for large-scale infrastructure systems. Left undetected, these types of corruptions can cause data loss and propagate across the stack and manifest as application-level problems.
Silent data corruptions (SDC) in hardware impact computational integrity for large-scale applications. Sources of corruptions include datapath dependencies, temperature variance, and age, among other silicon factors. These errors do not leave any record or trace in system logs. As a result, silent errors stay undetected within workloads and can propagate across several services. In this paper, we describe testing strategies to detect and mitigate silent data corruptions within a large-scale infrastructure. Given the challenging nature of the problem, we experimented with different methods for detection and mitigation. We compare and contrast two such approaches: 1) Fleetscanner (out-of-production testing) and 2) ripple (in-production testing). We evaluate the infrastructure trade-offs associated with the silicon testing funnel across 3+ years of production experience.
How silent error detection works
Within a typical manufacturing cycle, a server or a CPU gets tested at the vendor for a few hours, then at the integrator for a couple of days (in the best case), as well as on a sampling basis. However, once the components go through to a production fleet, it becomes really challenging to implement testing at scale. As a result, we need novel detection approaches for preserving application health and fleet resiliency by detecting SDCs and mitigating them at scale.
Every iteration of a test takes time away from production workloads. Out-of-production testing has a ramp-up and ramp-down between switching from test to production workloads. In-production testing can leave residual configs that might adversely affect workload performance. When we scale this to an entire fleet, the variations as well as the time needed for testing become significant. With in-production testing, the challenge is smart colocation with minimal effects. With out-of-production testing, the challenge is utilizing downtimes from production effectively without affecting other maintenance tasks.
At Meta, we implement multiple methods to detect SDCs, the two most effective of which are opportunistic and periodic testing and in-production/ripple testing. Opportunistic testing has been live within the fleet for around 3 years. However, in evaluating the trade-offs from one to the other, we’ve determined that both approaches are equally important to detecting SDCs, and we recommend using and deploying both in a large-scale fleet. We’ve observed that in-production testing can, within 15 days, detect 70 percent of the fleet data corruptions that opportunistic testing may take about 6 months to detect. However, the last 30 percent of the faults are only detectable with opportunistic testing, thus making both methods equally important for fault detection.
We’ve seen in our research that silent errors can happen during any set of functions within a data center CPU, and machines can encounter SDCs at different stages within the life cycle. Since these corruptions can cause latent problems to our infrastructure, we run a combination of proprietary and vendor-specific tests within our fleet to detect bad hardware.
We pursue two key methods to infrastructure testing:
- Out-of-production testing (opportunistic testing)
- In-production testing (ripple testing)
Opportunistic testing
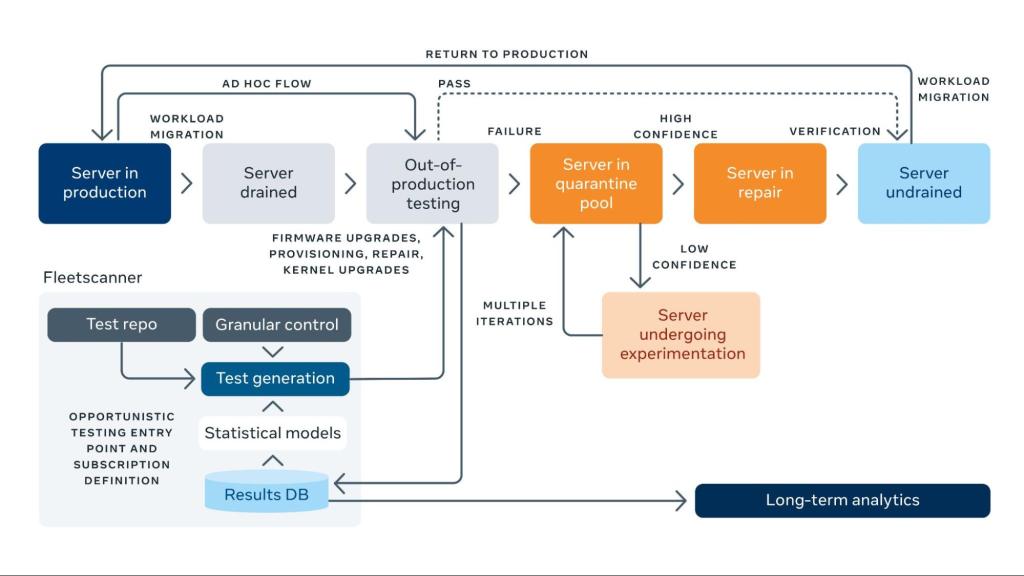
In a large-scale infrastructure, machines typically go through multiple maintenance events — either planned or unplanned maintenance. We rely on these maintenance events so we can piggyback on them and run SDC tests. System reboots, kernel upgrades, firmware upgrades, device reimages, host provisioning, and namespace reprovisioning and repairs are a few examples of maintenance events that have opportunistic testing enabled. We implement this mechanism using Fleetscanner, an internal facilitator tool for testing SDCs opportunistically.
Opportunistic testing allows for tests to have longer runtimes (on the order of minutes), enabling a more intrusive nature of detection. However, the inherent architecture of the opportunistic testing means it is possible to have corruptions in between two opportunistic test intervals on a suspect machine or CPU. We measured the testing cadence to evaluate the effectiveness of this testing mode. We’ve currently observed that through all the mechanisms described above, a machine goes through opportunistic testing an average of once every 180 days. This number is a combination of fleet population and upgrade cadences and varies based on machine type. There are fine-grained controls to enable more frequent opportunistic testing cadences on tiers and services that are sensitive.
Adding opportunistic testing to our fleet has meant that the majority of our maintenance activities have lengthened by the time it takes to conduct a test. As a result, we closely evaluate test time and testing frequencies for their detection efficacy.
Through this mechanism, we have achieved more than 68 million tests within the fleet, with a total test time machines have spent to be approximately 4 billion seconds opportunistically.
Ripple testing
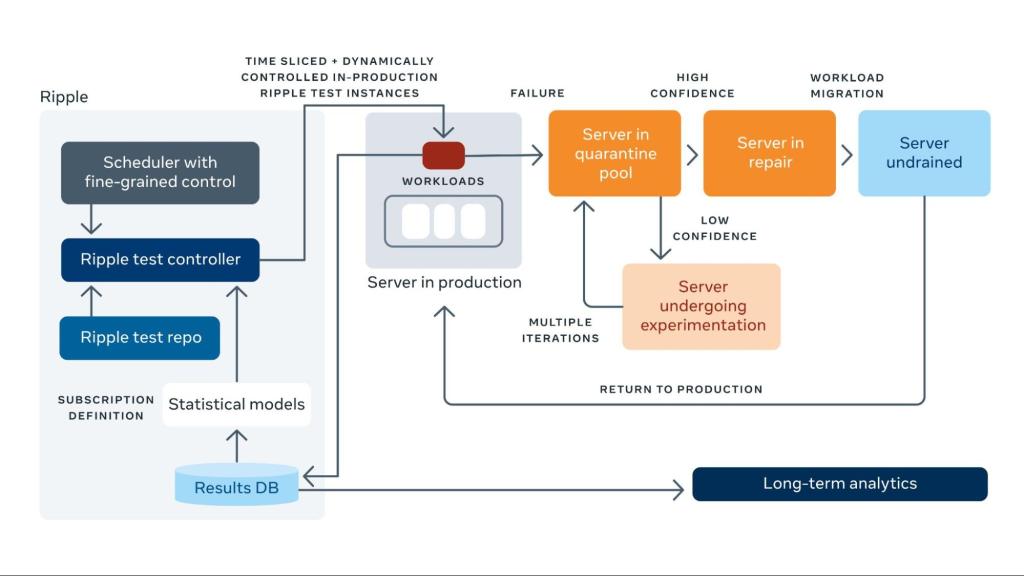
While opportunistic testing enabled frequent fleet coverage, it wasn’t sufficient to prevent production failures that manifested between testing windows, that were dependent on a different data pattern, or that happened because of the switch between different operating modes.
Ripple testing solves all the above problems by running silent error detection in conjunction with the workload. By carefully monitoring the nature of the workloads — shadow testing with the workloads and injecting bit patterns with expected results every now and then within the fleet (based on a predetermined cadence for a service) along with workloads — we can obtain coverage fleetwide at a significantly faster cadence. We enable granular controls to determine test intervals, test duration, and device configuration for tests to execute in colocation with the workloads.
Because the testing here “ripples” through our infrastructure, the test times are 1,000x lower than the opportunistic test runtimes. Ripple tests are typically in the order of hundreds of milliseconds within the fleet. They are scheduled based on workload behavior and can be switched on and off per workload. Because of the nature of defects and the scale-based approach of ripple testing, with unique seeds and creating more transition events, we are able to detect remote failures that could manifest only with thousands of iterations of the test. There is a footprint tax that we manage within the fleet to enable this testing, and we’ve observed it to be negligible in comparison with more frequent management activities. We shared our early results with CPU vendors, who have learned lessons from our fleet and implemented mechanisms within their tools to achieve similar results.
Through this mechanism, we run approximately 2.5 billion unique tests/test seeds within the fleet any given month. This framework has been live for the past couple of years within the fleet and has achieved a total test time of nearly 100 million seconds in colocation with the workloads.
The benefits of combining opportunist and ripple testing
While detecting SDCs is a challenging problem for large-scale infrastructures, years of testing have shown us that opportunistic and ripple testing can provide a novel solution for detecting SDCs at scale as quickly as possible.
| Metric | Opportunistic testing | Ripple testing |
| Seeds | ~68 million (lifetime) | ~2.5 billion (per month) |
| Testing time | ~4 billion fleet seconds (lifetime) | ~100 million fleet seconds (per month) |
| Performance aware | No | Yes |
| Unique SDC Coverage | 23 percent | 7 percent |
| Time to equivalent SDC coverage | ~6 months (70 percent) | ~15 days (70 percent) |
A comparison of the numbers presented in the above two sections is provided in the table. We observe that for defect types categorized within this paper, around 70 percent of the common coverage detection could be completed within 15 days. The opportunistic testing could catch up to the remaining 23 percent of the unique faulty CPUs for 6 months, and the remaining 7 percent is through repeated ripple instances within the fleet. There are benefits to both models of testing. We also consistently revisit and evaluate these coverage metrics to inform and update our fleetwide testing strategies around test vectors, test cadences, and test runtimes. We anticipate that with different types of defects, the coverage split may vary.
Historically, each CPU went through only a few hours of testing as part of infrastructure burn-in tests. Further testing was typically conducted via sampling. We observe that novel detection approaches are required for application health and fleet resiliency. We demonstrate the ability to test at scale and get through billions of seconds of testing every month across a large fleet consistently. These novel techniques enable us to detect silent data corruptions and mitigate them at scale.
Detecting silent data corruption is a challenging problem for large-scale infrastructures. Applications show significant sensitivity to these problems and can be exposed to such corruptions for months without accelerated detection mechanisms. It can also result in data loss and require months to debug and resolve software-level residue of silent corruptions. This research shows novel techniques resulting from years of experience observing silent corruptions and in categorizing their occurrence patterns and faster time to detection. Impact of silent data corruption can have a cascading effect on applications, and we have to address this as a critical problem. As a result, detecting these at scale as quickly as possible is an infrastructure priority toward enabling a safer, reliable fleet.
Request for proposals
To foster further innovation in this area and to deepen our collaboration with academia, Meta is inviting faculty to respond to this call for research proposals pertaining to the aforementioned topics. We anticipate giving up to five awards, each in the $50,000 range. Payment will be made to the proposer’s host university as an unrestricted gift.
Applications are open until March 22.
Read the full paper
-- to engineering.fb.com ","author":{"@type":"Person","name":"Tim Hartwell","url":"https://correctsuccess.com/author/emorystudio12-us/","sameAs":["http://correctsuccess.com"]},"articleSection":["Financial success","Money"],"image":{"@type":"ImageObject","url":"https://correctsuccess.com/wp-content/uploads/2022/04/Detecting-silent-errors-in-the-wild-Combining-two-novel-approaches.jpg","width":1920,"height":0},"publisher":{"@type":"Organization","name":"Correct Success","url":"https://correctsuccess.com","logo":{"@type":"ImageObject","url":"https://correctsuccess.com/wp-content/uploads/2020/10/Correct-Success-Logo-Design-PNG-3.png"},"sameAs":["https://www.facebook.com/TheCorrectSuccess/","https://twitter.com/correctsuccess","https://correctsuccess.tumblr.com/","https://in.pinterest.com/thecorrectsuccess/_saved/","https://www.instagram.com/correct_success/"]}}
Source link




